Data flow problem
WprowadzenieIntroduction
AbyTo skutecznieeffectively wprowadzićintegrate AI dointo EO iand umożliwićenable poszczególnymindividual chapteromchapters wykorzystanieto pełnifully możliwościleverage tejthe technologii,potential należyof najpierwthis rozwiazaćtechnology, problemthe przepływuissue danychof wewnątrzdata naszejflow organizacji.within our organization must first be addressed.
KażdyEach chapter posiadahas dwatwo głównemain rodzajetypes danych:of data:
DaneDataswojegospecificchapteru,toindywidualnetheirdlachapter,danegouniquechapterutoithatdostępnechaptertylkoanddlaaccessibleczłonkówonlydanegotochapteruits-membersjak–np.forinformacjeexample,oinformationczłonkachaboutchapteru,chapterbudżeciemembers,chapteru,chapterwewnętrznychbudgets,procedurachinternalchapteruchapteritp.procedures, etc.DaneDatawspólneshareddlaacrosscałegothe entire EO-–jaksuchoficjalneasmateriałyofficialszkoleniowetrainingomaterialsforum,forporadnikiforums,dlaguidesposzczególnychforczłonkówindividualzarządu,boardmateriałymembers,brandingoweand branding materials.
ObydwaBoth punktypoints wymagająrequire przemyśleniacareful iconsideration zaprojektowania,and aledesign, wbut tejin dyskusjithis chciałbymdiscussion, sięI skupićwould nalike punkcieto numerfocus on point number 2 -– czylidata danychshared wspólnychacross dlathe całegoentire EO.
ObecnyCurrent schematData przepływuFlow danychModel
WIn obecnymthe rozwiązaniucurrent AI dlasolution EOfor wykorzystujemyEO, oprogramowaniewe CogniVisuse AI.
Wthe CogniVis AI tworzymysoftware.
In instancjęCogniVis /AI, jednostkęwe oprogramowaniacreate dlaa każdegoseparate chapteru.instance/unit Dziękiof temuthe każdysoftware for each chapter. This ensures that each chapter mahas pełnięfull kontrolicontrol nadover swoimiits danymidata iand możecan swobodniefreely zarządzaćmanage kontamiuser użytkownikówaccounts dlafor swojegoits chapteru.chapter.
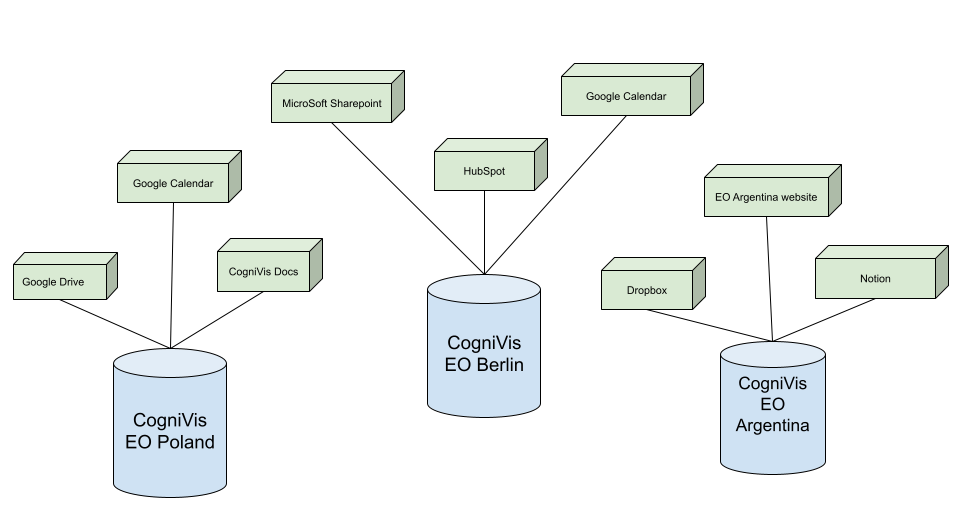
Link doto podgląduthe powyższegodiagram schematu:above: [https://docs.google.com/drawings/d/1PgJEkZtRAytCi81ziFLFp5_FqXDedBI6m-LUXUZshew/edit?usp=sharingsharing](https://docs.google.com/drawings/d/1PgJEkZtRAytCi81ziFLFp5
Legenda:Legend:
NiebieskiecylindryBlue
tocylindersinstancjerepresent CogniVisdlainstancesposzczególnychforchapterówindividual chapters (przykładowo dlae.g., EO Poland, EO Berlin, EO Argentina).ZieloneprostopadłościanyGreen
torectanglespodłączonerepresentźródłaconnecteddanychdata sources (tak zwaneso-called connectors)doforinstancjieachdanegochapter’schapteru.instance.KażdyEach chaptermożecanużywaćuseróżnychdifferentźródełdatadanychsources-–przykładowofor example, EO Polandmożemaykorzystaćuseze swojegoits Google Drive, EO Berlinzits MicrosoftSharepointSharePoint,aand EO ArgentinazitsDropboxa.Dropbox.-
Adding Data to a Chapter Instance
Dodawanie
Let's danychconsider doa instancjisimple chapteruexample:
Przyjmijmy następujący prosty przykład: każdyeach chapter chcewants dodaćto doadd swojejtwo instancjifiles 2to pliki,its abyinstance późniejso that AI mógłcan zlater nichuse korzystaćthem ito odpowiadaćrespond nato pytaniaquestions zrelated nimito związane:these files:
1. PierwszyThe plikfirst tofile arkuszis za danymispreadsheet członkówwith danegodata chapteruon the members of that chapter
PrzykładowyExample arkuszspreadsheet zwith danymimember członków:data: https://docs.google.com/spreadsheets/d/1BbusZF1i6689Je_JOENt4arsVNTTC9phJ0NmznI51Ug/edit?usp=sharing
KażdyEach chapter będziewill miałhave takisuch arkusza osobnospreadsheet dlaseparately, siebieand i każdyeach chapter chce,wants abyits tylkosheet jegoto członkowiebe mieliaccessible dostęponly doto jegoits arkusza.members.
KażdyThus, each chapter dodawill więcadd takithis arkuszspreadsheet (oznaczonymarked fioletowympurple koloremin nathe diagramiediagram poniżej)below) doto swojegoits źródładata danych.source. TrzymającFollowing sięour naszegoexample przykładowego schematuschema (see diagram poniżej)below):
-
EO Poland
dodawillarkuszadd the sheet "EO Poland Member Information Sheet"dotoswojegoits GoogleDriveDrive. -
EO Berlin
dodawillarkuszadd the sheet "EO Berlin Member Information Sheet"dotoswojegoits MicrosoftSharepointSharePoint. -
EO Argentina
dodawillarkuszadd the sheet "EO Argentina Member Information Sheet"dotoswojegoitsDropboxaDropbox.
2. DrugiThe pliksecond tofile is the PDF "SampleForumAgenda.pdf",pdf," którywhich jestis oficjalnyman dokumentemofficial ściągniętymdocument zedownloaded stronyfrom https://www.eonetwork.org/
WAgain, tym przypadku ponownie każdyeach chapter dodawill doadd swojegothis źródła danych wspomniany plikfile "SampleForumAgenda.pdf" (oznaczonymarked czerwonymred koloremin nathe diagramiediagram poniżej)below) to its data source.
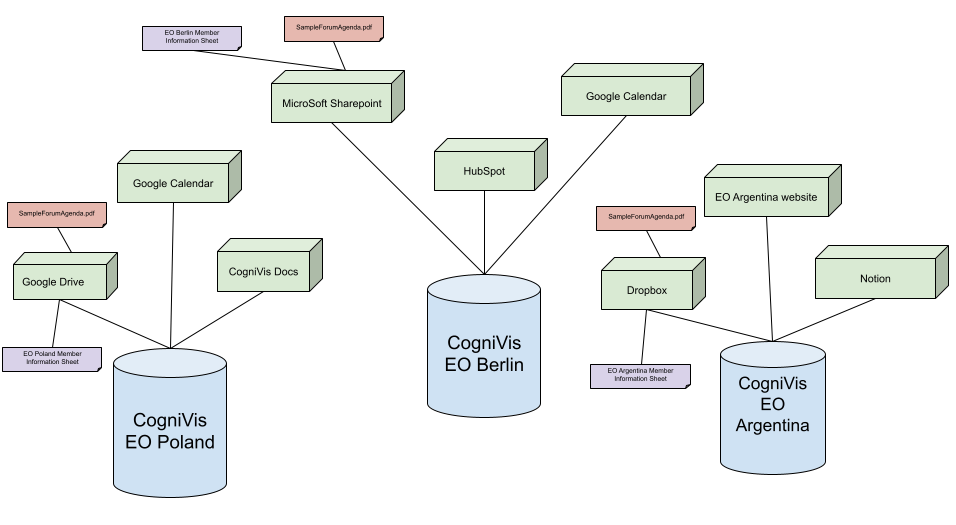
Link doto podgląduthe powyższegodiagram schematu:above: https://docs.google.com/drawings/d/1bv84hB65vT7kwyh99-chpx1RZiR2TwXHu-xFXwqT3pM/edit?usp=sharing
IstotnaProblem problemuAnalysis
WIn powyższymthe schemacieabove przepływudata danychflow słuszneschema, jest,it żeis każdycorrect that each chapter dodaadds doits swojejmember instancjidata sheet to its CogniVis arkuszinstance, zas danymi swoich członków, ponieważ każdyeach chapter będziewill miałhave tena plikdifferent innyfile, iand dostępaccess doshould niegobe powinienrestricted byćwithin ograniczonythat tylko w obrębie danej instancji.instance.
NatomiastHowever, sytuacjąit nieoptymalnąis jest,suboptimal żethat plikthe "SampleForumAgenda.pdf" równieżfile dodawanyis jestalso indywidualnieadded doindividually każdejto instancji,each pomimoinstance, tegodespite żebeing jestidentical identyczny,and acontaining zawartedata wshared nimby daneall sąEO wspólne dla wszystkich chapterów EO.chapters.
JeśliFor przykładowoexample, if EO Global wypuścireleases nowąa wersjęnew tegoversion pliku,of this file, all chapters will have to wszystkieupdate chapteryit będąindividually musiałyin indywidualnietheir dokonaćinstances, aktualizacji,adding każdaa nalot swojejof instancji.maintenance Dokładawork and creating risks, such as a chapter forgetting to mnóstwoupdate pracyand związanejusing zoutdated utrzymaniemversions iof tworzythe wieleofficial ryzyk,EO np.documents.
Moreover, jakiśthe issue becomes more complex considering the large volume of official EO data and documents, and the continuous release of new ones. If each chapter zapomnihas tegoto zrobićindividually iupdate niethese będziefiles, korzystaćdata zdiscrepancies najaktualniejszejwill wersjiquickly oficjalnychemerge, dokumentówleading EO.
Dodatkowoinconsistencies sprawęand, skomplikujeeventually, fakt,complete żedisarray, oficjalnychsignificantly danychreducing ithe dokumentóweffectiveness odof EOthe jestAI bardzothat wielerelies ion ciąglethis pojawiają się nowe. Jeśli każdy chapter będzie musiał indywidualnie dokonywać aktualizacji tych danych bardzo szybko pojawią się rozjazdy / różnice w tych danych, aż w końcu zapanuje zupełny bałagan, przez co efektywność sztucznej inteligencji, która na tych danych ma się opierać, bardzo spadnie.data.
RozwiązanieSolution iand sugerowanySuggested schematData przepływuFlow danychModel
NależyThe zmienićdata przepływflow danychshould tak,be abychanged oficjalneso dokumentythat ithe daneofficial zdocuments and data from EO Global, którewhich sąare wspólneshared dlaby wszystkichall chapterówEO EO,chapters, miałyhave swojea jednesingle źródło,source zfrom któregowhich następnie zaciągać będą dane wszystkie instancjeall CogniVis wszystkichinstances chapterów.for all chapters can pull data.
WIn tejthis sytuacjiscenario, daneindividual indywidualnedata (jaksuch arkuszeas zmember danymidata członkówsheets chapteru– -marked zaznaczonein napurple) fioletowo)would nadalstill będąbe indywidualnieadded dodawaneindividually przezby każdyeach chapter doto swojejits instnacji.own instance.
JednakHowever, danecommon wspólnedata dlafor całegothe entire EO (jaksuch plikas the "SampleForumAgenda.pdf" -file zaznaczony– namarked czerwono)in powinnyred) znajdowaćshould siębe wstored jednym,in oficjalnyma repozytoriumsingle, danychofficial EO Global,Global któredata zawierałobyrepository zawszethat najaktualniejszealways dane.contains the most up-to-date data.
WtedyThen, wszystkie instancjeall CogniVis wszystkichinstances chapterówfor all EO mogłybychapters zaciągaćcould oficjalnepull globalneofficial daneglobal zdata repozytoriumfrom the EO Global,Global arepository, swojewhile prywatneadding danetheir dodawaćprivate indywidualniedata doindividually swoichto instancji.their own instances.
DziękiThis temuwould znaczącosignificantly zmniejszyreduce sięthe ciężarmaintenance utrzymaniaburden danychof wspólnychshared dladata całegofor the entire EO, boas wystarczyit jewould utrzymywaćonly ineed aktualizowaćto tylkobe wmaintained jednymand miejscu.updated in one place.
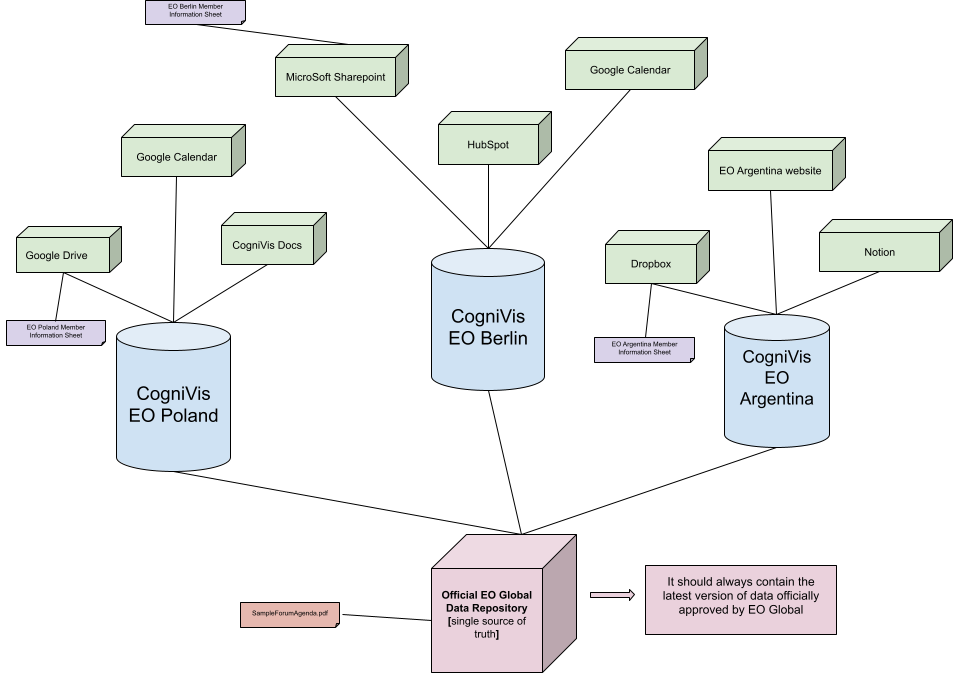
Link doto podgląduthe powyższegodiagram schematu:above: https://docs.google.com/drawings/d/1t2FvtLyfs-qvEVp2gA4pqaPdub46hZOI9KgwzRY8gPI/edit?usp=sharing
CzymWhat dokładnieExactly powinnoShould być Oficjalne Repozytorium Danychthe EO Global?Global Official Data Repository Be?
PoniżejBelow kilkaare propozycjisome isuggestions uwagand doconsiderations możliwychfor rozwiązań:possible solutions:
1. Cloud storageStorage
WIn najprostszymthe rozwiązaniusimplest mogłoby być to przygotowane przezsolution, EO Global could set up cloud storage (DyskGoogle Google,Drive, Microsoft Sharepoint,SharePoint, DropboxDropbox, itp),etc.) którethat byłobywould regularniebe utrzymywaneregularly imaintained aprobowaneand przezapproved zespółby the EO Global.Global team.
2. Komunikacja przez API zCommunication with https://hub.eonetwork.org/
BardziejA zaawansowanymmore rozwiązaniemadvanced byłobysolution umożliwieniewould bezpośredniejbe komunikacjienabling poprzezdirect API pomiędzycommunication instancjamibetween the CogniVis ainstances and https://hub.eonetwork.org/.
The question is whether the data on https://hub.eonetwork.org/ .
Pytanieregularly czymaintained daneand naalways https://hub.eonetwork.org/contains faktyczniethe sąlatest regularnieversions utrzymywaneof iall zawierają zawsze tylko najaktualniejsze wersje wszystkich dokumentów?documents.
ProblemIssue zwith plikamiPDFs PDFfor z oficjalnych dokumentówOfficial EO Global Documents
CogniVis AI dobrzeperforms radziwell sobiein z czytaniem plikówreading PDF ifiles znakomitejand, większościin udzielamost poprawnychcases, odpowiedziprovides nacorrect ichresponses podstawie.based on them.
Jednakże plikiHowever, PDF files (athe większośćformat dokumentówof most EO Global jestdocuments) ware takiejnot formie)the nieideal sąsolution najlepszymand rozwiązaniemcreate imany wlong-term długoterminowymcomplications, użytkowaniusuch tworzą wiele komplikacji, takich jak:as:
-
TrudnościDifficultieszinekstrakcjądatadanychextraction:StrukturaTheplikówstructure of PDFjestfilesprojektowanaisprzededesignedwszystkimprimarilydoforprezentacjivisualtreścipresentationwrathersposóbthanwizualny,storingaandnieprocessingdoinformationprzechowywaniabyi przetwarzania informacji przez maszyny.machines. AIczęstooftennapotykaencountersproblemyissueszinpoprawnymcorrectlyrozpoznawaniemrecognizingtekstu,text,tabel,tables,grafikgraphics,orazandukładudocumentdokumentu,layout,coleadingprowadzitodoerrorsbłędówinwdataekstrakcji danych.extraction. -
BrakLackspójnejofstruktury:consistentPliki PDF nie mają ujednoliconego standardu układu danych. Nawet w podobnych dokumentach formatowanie może się różnić, co utrudnia AI interpretację informacji, takich jak nagłówki, listy czy sekcje tekstu. Ograniczony dostęp do metadanych: W przeciwieństwie do innych formatów, takich jak JSON, XML czy CSV, pliki PDF nie zawierają strukturalnych metadanych, które mogą być łatwo analizowane przez algorytmy. To znacznie ogranicza możliwości wyszukiwania i filtrowania informacji.Problemy z kodowaniem znakówstructure: PDFmożefilesprzechowywaćdotekstnotwhaveróżnychaformatachunifiedkodowania,standardcoforczęstodatapowodujelayout.problemyEvenzinrozpoznawaniemsimilarniektórychdocuments,znaków,formattingszczególniemaywvary,dokumentachcomplicatingwielojęzycznychAI'slubinterpretationwofprzypadkuinformationniestandardowychsuchczcionek.as headers, lists, or text sections.-
NieefektywneLimitedprzetwarzanieaccessdanychtowielostronicowychmetadata:AlgorytmyUnlike other formats like JSON, XML, or CSV, PDF files do not contain structured metadata that can be easily analyzed by algorithms. This greatly limits the ability to search and filter information. - Character encoding issues: PDF can store text in different encoding formats, which often causes problems in recognizing certain characters, especially in multilingual documents or when using non-standard fonts.
-
Inefficient processing of multi-page data: AI
mogąalgorithmsmiećmaytrudnościstruggleztorozpoznawaniemrecognizekontekstu,contextjeśliwhentreścicontentsąispodzielonespreadnaacrosswielemultiplestron.pages.NaForprzykładexample,zdaniasentencesmogąmaybyćbreakprzerwaneatnathekońcuendjednejofstronyoneipagekontynuowaneandnacontinuenastępnej,oncothemożenext,skutkowaćleadingbłędnątointerpretacją.incorrect interpretations. -
BrakLackmożliwościofszybkiejefficientiandsprawnejquickaktualizacjiupdates:PDF-yPDFssąarezazwyczajgenerallystatyczne,static,comakingsprawia,themżeunsuitableniefornadajądynamicsięupdatesdoanddynamicznychautomaticaktualizacjidatairetrieval.automatycznegoForzaciąganiaAI,najnowszychthisdanych.meansWmanualkontekście AI oznaczaupdates tokoniecznośćsourceskażdorazowejareręcznejrequiredaktualizacjieachźródeł.time. -
TrudnościChallengeszinrozpoznawaniemrecognizingobrazówimages:CzęstoPDFPDF-yfileszawierająoftentekstcontainzapisanytextjakostoredobrazy,ascoimages,wymagawhichdodatkowegorequiresprzetwarzaniaadditionalzprocessingużyciemusing OCR (Optical Character Recognition),conotnieonlytylkolengtheningwydłużatheprocesanalysisanalizy,processalebuttakżealsomożepotentiallygenerowaćgeneratingbłędy,errors,zwłaszczaespeciallywwithprzypadkulow-qualityniskiej jakości skanów.scans. -
SkomplikowanaComplicatedanalizasemanticsemantycznaanalysis: AItrudniejhasjestdifficultyzrozumiećunderstandingkontekstcontextwinplikachPDFPDF,filesgdyżsinceteksttheczęstotextjestisrozmieszczonyoftenwarrangedsposóbinnieliniowya nonlinear manner (np.e.g.,winkolumnach,columnswstawionyorwinsertedramkach)in frames).MożeThis can lead toprowadzićmisinterpretationdoofbłędnejcontext,interpretacjimeaning,kontekstu,andsensurelationshipsibetweenzależnościtextpomiędzy fragmentami tekstu.fragments.
JestThis is a problem to problemsolve doin rozwiązaniathe na przyszłośćfuture (obecniecurrently, naweteven wykorzystującusing PDFyPDFs, możemywe dostaryczćcan wieledeliver wartościa zalot pomocąof value with AI dlafor EO). NatomaistHowever, docelowothe należałobyultimate wymyślećgoal innewould rozwiązanie.be Potrzebnyto byłbydevise jakiśa different solution. A document management system zarządzaniawould dokumentami,be któryneeded umożłiwiałbythat tworzeniewould optymalnejallow strukturyfor dlathe creation of an optimal structure for AI orazand łatwąeasy aktualizację.updates.
PodsumowanieSummary
MusimyWe przedeprimarily wszystkimneed znaleźćto rozwiązaniefind dlaa Oficjalnegosolution Repozytoriumfor Danychthe EO Global.Global PotraktujcieOfficial tenData dokumentRepository. jakoTreat otwarciethis burzydocument mózgówas ithe wbeginning komentarzachof napiszciea pomysłybrainstorming nasession rozwiązanieand tegoshare wyzwania.your ideas for addressing this challenge in the comments.