Data flow problem
Wprowadzenie
Aby skutecznie wprowadzić AI do EO i umożliwić poszczególnym chapterom wykorzystanie pełni możliwości tej technologii, należy najpierw rozwiazać problem przepływu danych wewnątrz naszej organizacji.
Każdy chapter posiada dwa główne rodzaje danych:
- Dane swojego chapteru, indywidualne dla danego chapteru i dostępne tylko dla członków danego chapteru - jak np. informacje o członkach chapteru, budżecie chapteru, wewnętrznych procedurach chapteru itp.
- Dane wspólne dla całego EO - jak oficjalne materiały szkoleniowe o forum, poradniki dla poszczególnych członków zarządu, materiały brandingowe
Obydwa punkty wymagają przemyślenia i zaprojektowania, ale w tej dyskusji chciałbym się skupić na punkcie numer 2 - czyli danych wspólnych dla całego EO.
Obecny schemat przepływu danych
W obecnym rozwiązaniu AI dla EO wykorzystujemy oprogramowanie CogniVis AI.
W CogniVis AI tworzymy osobną instancję / jednostkę oprogramowania dla każdego chapteru. Dzięki temu każdy chapter ma pełnię kontroli nad swoimi danymi i może swobodnie zarządzać kontami użytkowników dla swojego chapteru.
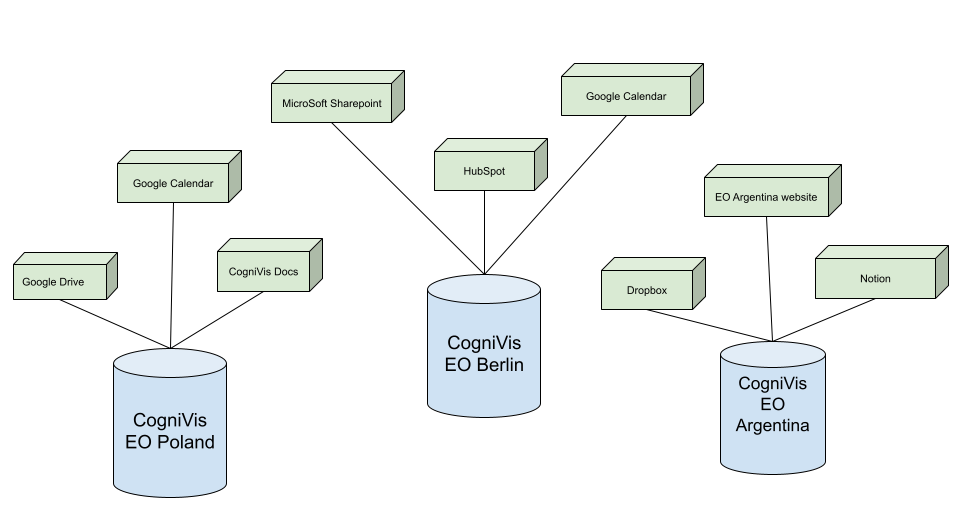
Link do podglądu powyższego schematu: https://docs.google.com/drawings/d/1PgJEkZtRAytCi81ziFLFp5_FqXDedBI6m-LUXUZshew/edit?usp=sharing
Legenda:
- Niebieskie cylindry to instancje CogniVis dla poszczególnych chapterów (przykładowo dla EO Poland, EO Berlin, EO Argentina)
- Zielone prostopadłościany to podłączone źródła danych (tak zwane connectors) do instancji danego chapteru. Każdy chapter może używać różnych źródeł danych - przykładowo EO Poland może korzystać ze swojego Google Drive, EO Berlin z Microsoft Sharepoint a EO Argentina z Dropboxa.
Dodawanie danych do instancji chapteru
Przyjmijmy następujący prosty przykład: każdy chapter chce dodać do swojej instancji 2 pliki, aby później AI mógł z nich korzystać i odpowiadać na pytania z nimi związane:
1. Pierwszy plik to arkusz z danymi członków danego chapteru
Przykładowy arkusz z danymi członków: https://docs.google.com/spreadsheets/d/1BbusZF1i6689Je_JOENt4arsVNTTC9phJ0NmznI51Ug/edit?usp=sharing
Każdy chapter będzie miał taki arkusz osobno dla siebie i każdy chapter chce, aby tylko jego członkowie mieli dostęp do jego arkusza.
Każdy chapter doda więc taki arkusz (oznaczony fioletowym kolorem na diagramie poniżej) do swojego źródła danych. Trzymając się naszego przykładowego schematu (diagram poniżej):
- EO Poland doda arkusz "EO Poland Member Information Sheet" do swojego Google Drive
- EO Berlin doda arkusz "EO Berlin Member Information Sheet" do swojego Microsoft Sharepoint
- EO Argentina doda arkusz "EO Argentina Member Information Sheet" do swojego Dropboxa
2. Drugi plik to PDF "SampleForumAgenda.pdf", który jest oficjalnym dokumentem ściągniętym ze strony https://www.eonetwork.org/
W tym przypadku ponownie każdy chapter doda do swojego źródła danych wspomniany plik "SampleForumAgenda.pdf" (oznaczony czerwonym kolorem na diagramie poniżej)
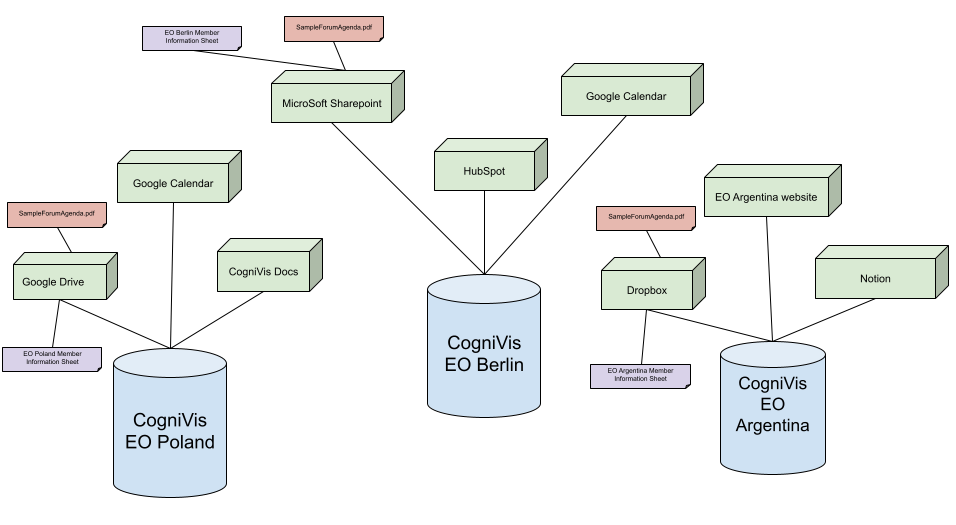
Link do podglądu powyższego schematu: https://docs.google.com/drawings/d/1bv84hB65vT7kwyh99-chpx1RZiR2TwXHu-xFXwqT3pM/edit?usp=sharing
Istotna problemu
W powyższym schemacie przepływu danych słuszne jest, że każdy chapter doda do swojej instancji CogniVis arkusz z danymi swoich członków, ponieważ każdy chapter będzie miał ten plik inny i dostęp do niego powinien być ograniczony tylko w obrębie danej instancji.
Natomiast sytuacją nieoptymalną jest, że plik "SampleForumAgenda.pdf" również dodawany jest indywidualnie do każdej instancji, pomimo tego że jest identyczny, a zawarte w nim dane są wspólne dla wszystkich chapterów EO.
Jeśli przykładowo EO Global wypuści nową wersję tego pliku, to wszystkie chaptery będą musiały indywidualnie dokonać aktualizacji, każda na swojej instancji. Dokłada to mnóstwo pracy związanej z utrzymaniem i tworzy wiele ryzyk, np. że jakiś chapter zapomni tego zrobić i nie będzie korzystać z najaktualniejszej wersji oficjalnych dokumentów EO.
Dodatkowo sprawę skomplikuje fakt, że oficjalnych danych i dokumentów od EO jest bardzo wiele i ciągle pojawiają się nowe. Jeśli każdy chapter będzie musiał indywidualnie dokonywać aktualizacji tych danych bardzo szybko pojawią się rozjazdy / różnice w tych danych, aż w końcu zapanuje zupełny bałagan, przez co efektywność sztucznej inteligencji, która na tych danych ma się opierać, bardzo spadnie.
Rozwiązanie i sugerowany schemat przepływu danych
Należy zmienić przepływ danych tak, aby oficjalne dokumenty i dane z EO Global, które są wspólne dla wszystkich chapterów EO, miały swoje jedne źródło, z którego następnie zaciągać będą dane wszystkie instancje CogniVis wszystkich chapterów.
W tej sytuacji dane indywidualne (jak arkusze z danymi członków chapteru - zaznaczone na fioletowo) nadal będą indywidualnie dodawane przez każdy chapter do swojej instnacji.
Jednak dane wspólne dla całego EO (jak plik "SampleForumAgenda.pdf" - zaznaczony na czerwono) powinny znajdować się w jednym, oficjalnym repozytorium danych EO Global, które zawierałoby zawsze najaktualniejsze dane.
Wtedy wszystkie instancje CogniVis wszystkich chapterów EO mogłyby zaciągać oficjalne globalne dane z repozytorium EO Global, a swoje prywatne dane dodawać indywidualnie do swoich instancji.
Dzięki temu znacząco zmniejszy się ciężar utrzymania danych wspólnych dla całego EO, bo wystarczy je utrzymywać i aktualizować tylko w jednym miejscu.
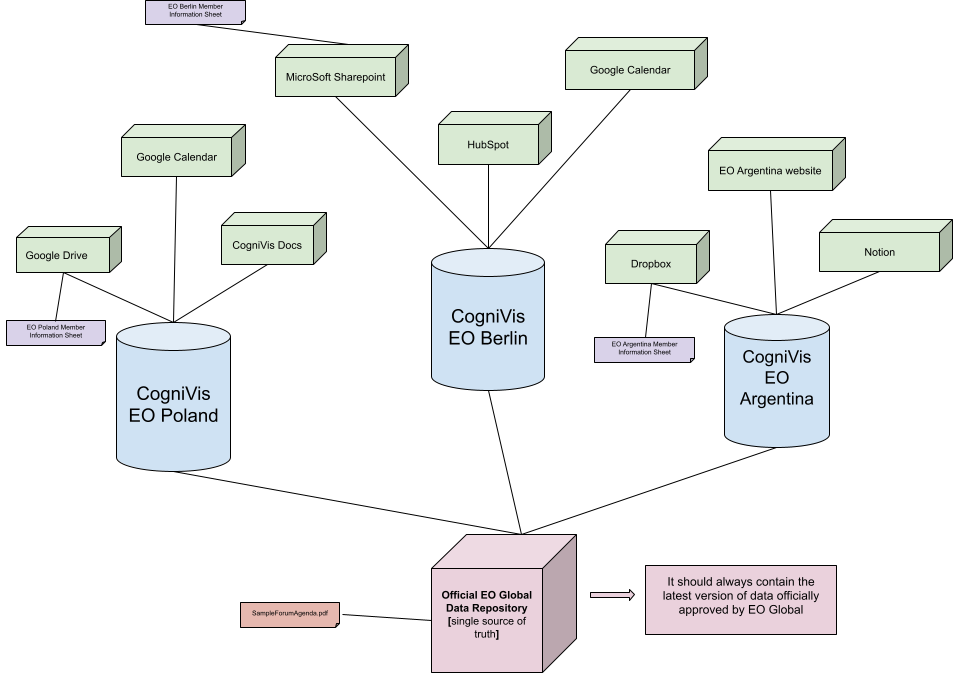
Link do podglądu powyższego schematu: https://docs.google.com/drawings/d/1t2FvtLyfs-qvEVp2gA4pqaPdub46hZOI9KgwzRY8gPI/edit?usp=sharing
Czym dokładnie powinno być Oficjalne Repozytorium Danych EO Global?
Poniżej kilka propozycji i uwag do możliwych rozwiązań:
1. Cloud storage
W najprostszym rozwiązaniu mogłoby być to przygotowane przez EO Global cloud storage (Dysk Google, Microsoft Sharepoint, Dropbox itp), które byłoby regularnie utrzymywane i aprobowane przez zespół EO Global.
2. Komunikacja przez API z https://hub.eonetwork.org/
Bardziej zaawansowanym rozwiązaniem byłoby umożliwienie bezpośredniej komunikacji poprzez API pomiędzy instancjami CogniVis a https://hub.eonetwork.org/ .
Pytanie czy dane na https://hub.eonetwork.org/ faktycznie są regularnie utrzymywane i zawierają zawsze tylko najaktualniejsze wersje wszystkich dokumentów?
Problem z plikami PDF z oficjalnych dokumentów EO Global
CogniVis AI dobrze radzi sobie z czytaniem plików PDF i znakomitej większości udziela poprawnych odpowiedzi na ich podstawie.
Jednakże pliki PDF (a większość dokumentów EO Global jest w takiej formie) nie są najlepszym rozwiązaniem i w długoterminowym użytkowaniu tworzą wiele komplikacji, takich jak:
Trudności z ekstrakcją danych: Struktura plików PDF jest projektowana przede wszystkim do prezentacji treści w sposób wizualny, a nie do przechowywania i przetwarzania informacji przez maszyny. AI często napotyka problemy z poprawnym rozpoznawaniem tekstu, tabel, grafik oraz układu dokumentu, co prowadzi do błędów w ekstrakcji danych.
Brak spójnej struktury: Pliki PDF nie mają ujednoliconego standardu układu danych. Nawet w podobnych dokumentach formatowanie może się różnić, co utrudnia AI interpretację informacji, takich jak nagłówki, listy czy sekcje tekstu.
Ograniczony dostęp do metadanych: W przeciwieństwie do innych formatów, takich jak JSON, XML czy CSV, pliki PDF nie zawierają strukturalnych metadanych, które mogą być łatwo analizowane przez algorytmy. To znacznie ogranicza możliwości wyszukiwania i filtrowania informacji.
Problemy z kodowaniem znaków: PDF może przechowywać tekst w różnych formatach kodowania, co często powoduje problemy z rozpoznawaniem niektórych znaków, szczególnie w dokumentach wielojęzycznych lub w przypadku niestandardowych czcionek.
Nieefektywne przetwarzanie danych wielostronicowych: Algorytmy AI mogą mieć trudności z rozpoznawaniem kontekstu, jeśli treści są podzielone na wiele stron. Na przykład zdania mogą być przerwane na końcu jednej strony i kontynuowane na następnej, co może skutkować błędną interpretacją.
Brak możliwości szybkiej i sprawnej aktualizacji: PDF-y są zazwyczaj statyczne, co sprawia, że nie nadają się do dynamicznych aktualizacji i automatycznego zaciągania najnowszych danych. W kontekście AI oznacza to konieczność każdorazowej ręcznej aktualizacji źródeł.
Trudności z rozpoznawaniem obrazów: Często PDF-y zawierają tekst zapisany jako obrazy, co wymaga dodatkowego przetwarzania z użyciem OCR (Optical Character Recognition), co nie tylko wydłuża proces analizy, ale także może generować błędy, zwłaszcza w przypadku niskiej jakości skanów.
Skomplikowana analiza semantyczna: AI trudniej jest zrozumieć kontekst w plikach PDF, gdyż tekst często jest rozmieszczony w sposób nieliniowy (np. w kolumnach, wstawiony w ramkach). Może to prowadzić do błędnej interpretacji kontekstu, sensu i zależności pomiędzy fragmentami tekstu.
Jest to problem do rozwiązania na przyszłość (obecnie nawet wykorzystując PDFy możemy dostaryczć wiele wartości za pomocą AI dla EO). Natomaist docelowo należałoby wymyśleć inne rozwiązanie. Potrzebny byłby jakiś system zarządzania dokumentami, który umożłiwiałby tworzenie optymalnej struktury dla AI oraz łatwą aktualizację.
Podsumowanie
Musimy przede wszystkim znaleźć rozwiązanie dla Oficjalnego Repozytorium Danych EO Global. Potraktujcie ten dokument jako otwarcie burzy mózgów i w komentarzach napiszcie pomysły na rozwiązanie tego wyzwania.