Data flow problem
Wprowadzenie
Aby skutecznie wprowadzić AI do EO i umożliwić poszczególnym chapterom wykorzystanie pełni możliwości tej technologii, należy najpierw rozwiazać problem przepływu danych wewnątrz naszej organizacji.
Każdy chapter posiada dwa główne rodzaje danych:
- Dane swojego chapteru, indywidualne dla danego chapteru i dostępne tylko dla członków danego chapteru - jak np. informacje o członkach chapteru, budżecie chapteru, wewnętrznych procedurach chapteru itp.
- Dane wspólne dla całego EO - jak oficjalne materiały szkoleniowe o forum, poradniki dla poszczególnych członków zarządu, materiały brandingowe
Obydwa punkty wymagają przemyślenia i zaprojektowania, ale w tej dyskusji chciałbym się skupić na punkcie numer 2 - czyli danych wspólnych dla całego EO.
Obecny schemat przepływu danych
W obecnym rozwiązaniu AI dla EO wykorzystujemy oprogramowanie CogniVis AI.
W CogniVis AI tworzymy osobną instancję / jednostkę oprogramowania dla każdego chapteru. Dzięki temu każdy chapter ma pełnię kontroli nad swoimi danymi i może swobodnie zarządzać kontami użytkowników dla swojego chapteru.
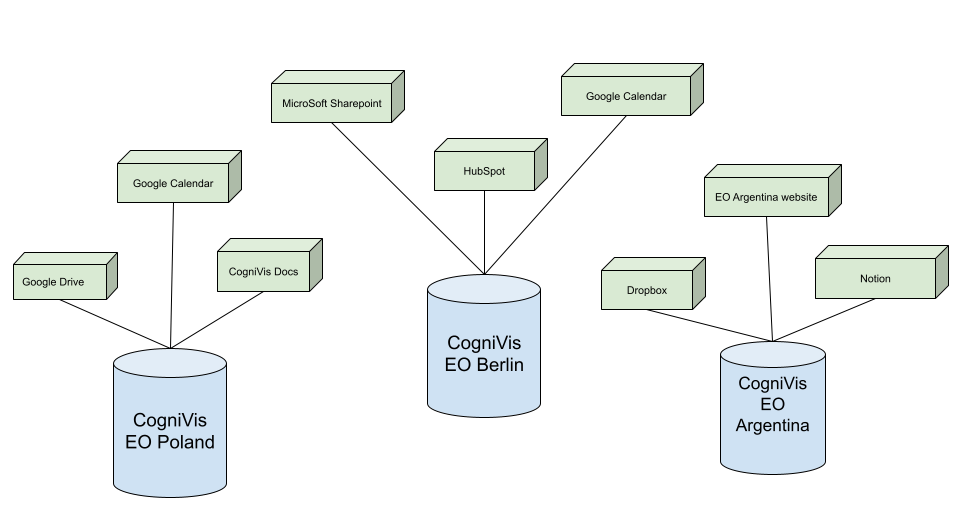
Link do podglądu powyższego schematu: https://docs.google.com/drawings/d/1PgJEkZtRAytCi81ziFLFp5_FqXDedBI6m-LUXUZshew/edit?usp=sharing
Legenda:
- Niebieskie cylindry to instancje CogniVis dla poszczególnych chapterów (przykładowo dla EO Poland, EO Berlin, EO Argentina)
- Zielone prostopadłościany to podłączone źródła danych (tak zwane connectors) do instancji danego chapteru. Każdy chapter może używać różnych źródeł danych - przykładowo EO Poland może korzystać ze swojego Google Drive, EO Berlin z Microsoft Sharepoint a EO Argentina z Dropboxa.